With Power BI Desktop you can use the Azure HDInsight Spark BI Connector to get data from the Spark cluster to build reports. I have an HDInsight Spark 2.0 cluster with Azure Data Lake Store as the primary storage.
Open Power BI Desktop
Click Get Data

Enter url of your HDInsight Spark cluster.
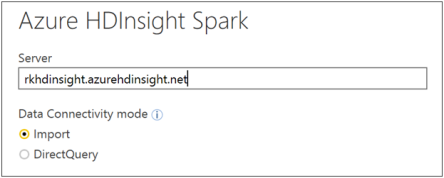
Enter the cluster admin credentials. This is the same credentials for Ambari.
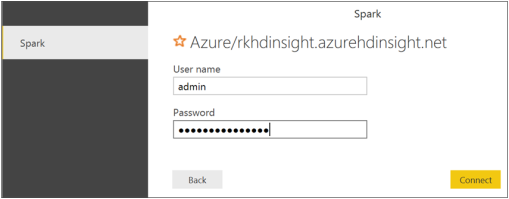
We are able to see a list of tables and views along with a preview of data. In my case, usdata is the database. Crimes and crimesgroupbytype are internal hive tables, crimes_ext is an external table and crimesgroupbytype_view is a view.
I selected crimes, crimesgroupbytype and crimesgroupbytype_view.
Click Load to generate queries for each
The Query Editor

When I click Apply & Close, the crimes query results in an error. My suspicion is that crimes has over a million rows where the other queries are only dealing with several hundred rows. Since this connector is in beta, perhaps I have to wait for final release.

To continue, I delete usdata crimes query.

Click Close & Apply
In Report Page you can see your tables in Fields pane from the two queries

I build my report of number of crimes by each crime. Also filters to the right on year and crime type.

HDInsight and Power BI is a powerful combination to work with big data and the ability to transform, analyze and visualize data with Power BI desktop.
